%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Image Understanding
VLM R1
VLM-R1 is a reinforcement learning-based visual-language model focused on visual understanding tasks, such as Referring Expression Comprehension (REC). By combining Reinforcement Learning (R1) and Supervised Fine-Tuning (SFT) methods, this model demonstrates excellent performance on both in-domain and out-of-domain data. The main advantages of VLM-R1 include its stability and generalization ability, enabling it to excel in various visual-language tasks. Built upon Qwen2.5-VL, the model leverages advanced deep learning techniques like Flash Attention 2 to enhance computational efficiency. VLM-R1 aims to provide an efficient and reliable solution for visual-language tasks, suitable for applications requiring precise visual understanding.
AI Model
61.0K
Kimi Latest
kimi-latest is the latest AI model launched by Moonshot AI, synchronously upgraded with the Kimi intelligent assistant. It has powerful context processing capabilities and automatic caching functions, which can effectively reduce usage costs. The model supports image understanding and multiple functions such as ToolCalls and web search, making it suitable for building AI-powered intelligent assistants or customer service systems. Priced at ¥1 per million tokens, it is positioned as an efficient and flexible AI model solution.
AI Model
86.7K

Janus Pro
Janus Pro is an advanced AI image generation and understanding platform powered by DeepSeek technology. It employs a revolutionary unified transformer architecture to efficiently handle complex multimodal operations, delivering exceptional performance in image generation and understanding. The platform has trained on over 90 million samples, including 72 million synthesized aesthetic data points, ensuring that generated images are visually appealing and contextually accurate. Janus Pro provides developers and researchers with powerful visual AI capabilities to assist them in transforming ideas into visual narratives. The platform offers a free trial, making it suitable for users needing high-quality image generation and analysis.
Image Generation
83.9K
Videollama3
VideoLLaMA3, developed by the DAMO-NLP-SG team, is a state-of-the-art multimodal foundational model specializing in image and video understanding. Based on the Qwen2.5 architecture, it integrates advanced visual encoders (such as SigLip) with powerful language generation capabilities to address complex visual and language tasks. Key advantages include efficient spatiotemporal modeling, strong multimodal fusion capabilities, and optimized training on large-scale datasets. This model is suitable for applications requiring deep video understanding, such as video content analysis and visual question answering, demonstrating significant potential for both research and commercial use.
Video Production
56.3K
Qwen2 VL 2B
Qwen2-VL-2B is the latest iteration of the Qwen-VL model, representing nearly a year's worth of innovations. The model has achieved state-of-the-art performance on visual understanding benchmarks including MathVista, DocVQA, RealWorldQA, and MTVQA. It can comprehend over 20-minute videos, providing high-quality support for video-based question answering, dialogue, and content creation. Qwen2-VL also supports multiple languages, including most European languages, Japanese, Korean, Arabic, Vietnamese, in addition to English and Chinese. Model architecture updates include Naive Dynamic Resolution and Multimodal Rotary Position Embedding (M-ROPE), which enhance its multimodal processing capabilities.
AI Model
48.0K
Onediffusion
OneDiffusion is a versatile, large-scale diffusion model capable of seamlessly supporting bidirectional image synthesis and understanding across a variety of tasks. The model is expected to release its code and checkpoints in early December. The significance of OneDiffusion lies in its ability to handle tasks related to image synthesis and understanding, marking an important advancement in the field of artificial intelligence, especially in image generation and recognition. Background information indicates that this is a collaborative project developed by multiple researchers, and the research outcomes have been published on arXiv.
Image Generation
51.9K
Pixtral Large Instruct 2411
Pixtral-Large-Instruct-2411, developed by Mistral AI, is a large multimodal model with 124 billion parameters, built on Mistral Large 2. It showcases state-of-the-art image understanding capabilities, capable of interpreting documents, charts, and natural images while maintaining a lead in text comprehension from Mistral Large 2. The model achieves advanced performance on datasets like MathVista, DocVQA, and VQAv2, making it a powerful tool for research and business applications.
Large Language Model
51.9K
English Picks

Pixtral Large
Pixtral Large is a cutting-edge multimodal AI model introduced by Mistral AI, built upon Mistral Large 2. It features advanced image understanding capabilities, enabling comprehension of documents, charts, and natural images while retaining Mistral Large 2's leadership in text understanding. The model has demonstrated exceptional performance in multimodal benchmarks, surpassing other models in tests such as MathVista, ChartQA, and DocVQA. It has also shown competitiveness in the MM-MT-Bench tests, outperforming various models, including Claude-3.5 Sonnet. The model is available under the Mistral Research License (MRL) for research and educational purposes and the Mistral Commercial License for commercial use.
Multimodal
55.2K
MM1.5
MM1.5 is a series of multimodal large language models (MLLMs) designed to enhance capabilities in understanding text-rich images, visual reference grounding, and multi-image reasoning. Based on the MM1 architecture, the model adopts a data-centric training approach and systematically explores the impact of different data mixes throughout the model training lifecycle. The MM1.5 model varies from 1B to 30B parameters and includes both dense and mixture of experts (MoE) variants, providing valuable guidance for future MLLM development research through extensive empirical and ablation studies that detail the training processes and decision insights.
AI Model
46.6K
Mplug Owl3
mPLUG-Owl3 is a multimodal large language model focused on understanding long image sequences. It can learn knowledge from retrieval systems, engage in alternating image-text dialogues with users, and watch long videos while remembering the details. The model's source code and weights have been released on HuggingFace, suitable for tasks like visual question answering, multimodal benchmark testing, and video benchmarking.
AI Model
51.6K
Phi 3.5 Vision
Phi-3.5-vision is a lightweight, next-generation multimodal model developed by Microsoft. It is built on a dataset that includes synthetic data and curated publicly available websites, focusing on high-quality, dense reasoning data for both text and visual inputs. This model belongs to the Phi-3 family and has undergone rigorous enhancement processes, combining supervised fine-tuning with direct preference optimization to ensure precise instruction following and robust safety measures.
AI Model
55.2K
Minicpm V 2.6
MiniCPM-V 2.6 is a multimodal large language model based on 800 million parameters, demonstrating leading performance in single image understanding, multiple image understanding, and video comprehension across various domains. The model achieved an average score of 65.2 on multiple popular benchmarks such as OpenCompass, surpassing widely used proprietary models. It possesses robust OCR capabilities, supports multiple languages, and performs efficiently, enabling real-time video understanding on devices like the iPad.
AI Model
53.5K
Fresh Picks
Internlm XComposer 2.5
InternLM-XComposer-2.5 is a multifunctional large visual language model that supports long context input and output. It excels in various text-image understanding and generation applications, achieving performance comparable to GPT-4V while utilizing only 7B parameters for its LLM backend. Trained on 24K interleaved image-text context, the model seamlessly scales to 96K long context through RoPE extrapolation. This long context capability makes it particularly adept at tasks requiring extensive input and output context. Furthermore, it supports ultra-high resolution understanding, fine-grained video understanding, multi-turn multi-image dialogue, web page creation, and writing high-quality text-image articles.
AI Model
73.4K
Fresh Picks
Paligemma
PaliGemma is an advanced vision-language model released by Google. It combines the image encoder SigLIP and the text decoder Gemma-2B to understand both images and text, achieving interactive understanding through joint training. This model is designed for specific downstream tasks such as image description, visual question answering, and segmentation, serving as a crucial tool in research and development.
AI image detection and recognition
51.1K

Minigemini
Mini-Gemini is a multimodal visual language model supporting a series of dense and MoE large language models ranging from 2B to 34B. It possesses capabilities for image understanding, reasoning, and generation. Based on LLaVA, it utilizes dual vision encoders to provide low-resolution visual embeddings and high-resolution candidate regions. It employs patch-level information mining to perform patch-level mining between high-resolution regions and low-resolution visual queries, fusing text and images for understanding and generation tasks. It supports multiple visual understanding benchmark tests, including COCO, GQA, OCR-VQA, and VisualGenome.
AI image generation
153.5K
Chinese Picks
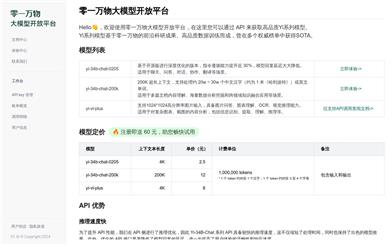
Zero & All Things Large Model Open Platform
The Zero & All Things Large Model Open Platform is a platform that provides access to high-quality Zero & All Things large models through API calls. The Yi series models are based on the cutting-edge research achievements and high-quality data training of Zero & All Things, and have achieved SOTA performance on multiple authoritative lists. The main products include yi-34b-chat-0205, yi-34b-chat-200k, and yi-vl-plus models. yi-34b-chat-0205 is an optimized chat model with an improved instruction compliance ability by nearly 30%, significantly reduced response latency, suitable for chat, Q&A, and dialogue scenarios. yi-34b-chat-200k supports up to 200K long contexts and can process content of approximately 200,000 to 300,000 Chinese characters, suitable for document understanding, data analysis, and cross-domain knowledge application. yi-vl-plus supports high-resolution image input and possesses capabilities of image Q&A, chart understanding, OCR, and is suitable for analyzing, recognizing, and understanding complex image content. The API advantages of this platform include fast inference speed and full compatibility with the OpenAI API. In terms of pricing, new registered users receive a 60 yuan trial amount, yi-34b-chat-0205 is priced at 2.5 yuan per million tokens, yi-34b-chat-200k is priced at 12 yuan per session, and yi-vl-plus is priced at 6 yuan per million tokens.
API Services
213.3K
Vary
Vary is an official code implementation for large-scale visual language models. It enhances model performance by expanding the visual vocabulary. The model boasts strong image understanding and language generation capabilities, applicable across multiple domains.
AI image generation
85.8K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.5K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.3K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.5K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M